[디지털경제뉴스 박시현 기자] 한국 HPE는 신규 HPE 머신러닝 개발 시스템(HPE Machine Learning Development System)으로 기업 규모에 최적화된 머신러닝 모델 구축 및 학습 환경을 제공하며 더욱 빠른 가치 실현을 지원한다고 밝혔다.
AI에 최적화된 신규 시스템은 머신러닝 소프트웨어 플랫폼, 컴퓨팅, 가속기, 네트워킹을 통합해 보다 정확하고 빠르게 규모에 최적화된 AI 모델을 개발하고 학습시킨다.
<그림>HPE 머신러닝 개발 시스템
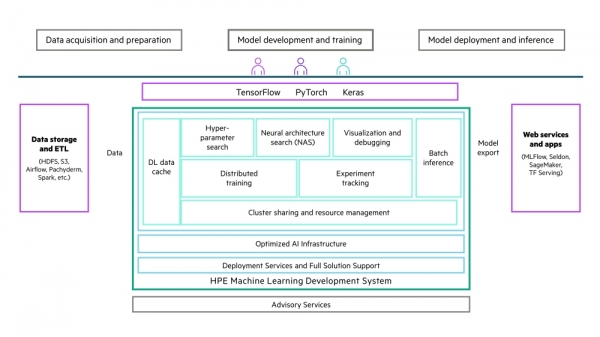
HPE 머신러닝 개발 시스템은 디터민드 AI(Determined AI) 인수 등 현재 HPE 머신러닝 개발 환경(HPE Machine Learning Development Environment)으로 알려진 머신러닝 플랫폼과 AI 및 고성능 컴퓨팅(HPC) 솔루션을 결합하기 위한 전략적 투자를 기반으로 하고 있다.
사용자는 신규 솔루션을 통해 머신러닝 모델 구축 및 학습을 바탕으로 기존 분석 결과에 소요되던 가치 실현 시간을 수 주 및 수 개월에서 수일로 단축할 수 있다.
◆독일 AI 스타트업 알레프 알파, 기록적인 속도로 대규모 멀티모달 AI 모델 학습 돌입 = HPE는 독일의 AI 스타트업인 알레프 알파(Aleph Alpha)가 자연어 처리(NLP)와 컴퓨터 비전을 포함한 멀티모달 AI를 학습시키기 위해 HPE 머신러닝 개발 시스템을 채택했다고 밝혔다.
알레프 알파는 5개의 언어로 구성된 이미지 및 텍스트 처리를 인간의 인지 능력과 유사한 수준으로 결합해 복잡한 텍스트 생성, 고도의 인지능력이 요구되는 요약본, 수백 개의 문서 내 구체적인 정보 검색, 대화 중 전문 지식 활용 등 다양한 종류의 언어와 이미지 기반의 혁신적 사용 사례를 제공하며 현재의 AI 기술 경계의 범위를 확장했다.
알레프 알파는 HPE 머신러닝 개발 시스템의 도입으로 수백 개의 GPU를 통합 및 모니터링하며 획기적인 수준으로 시스템을 빠르고 효율적이게 운영할 수 있게 됐다.
알레프 알파 설립자 겸 CEO 요나스 안드룰리스(Jonas Andrulis)는 "HPE 머신 러닝 개발 시스템 도입 후, 150 테라플롭 이상의 놀라운 효율성 및 성과를 달성하고 있으며, 더욱 빠른 시스템 구축으로 기존 수 주가 소요되던 모델 학습 기간을 몇 시간 단위로 단축했다”며 “현재 진행 중인 연구뿐만 아니라 대규모 워크로드 운영 서비스도 함께 제공하는 HPE 머신러닝 개발 시스템의 구현 및 모니터링 통합 솔루션이야말로 큰 차이를 만든다”고 말했다.
HPE의 HPC&AI 부사장 겸 제너럴 매니저 저스틴 호타드(Justin Hotard)는 "기업은 자사의 제품과 서비스를 차별화하기 위해 AI와 머신러닝을 통합하려고 하지만 규모에 맞는 정확한 AI 모델을 구축하고 학습하는 데 필요한 인프라 구축에 있어 복잡성이라는 이슈에 직면한다"며 "HPE 머신러닝 개발 시스템은 검증된 딥러닝용 엔드투엔드 HPC 솔루션과 혁신적인 머신러닝 소프트웨어 플랫폼을 하나의 시스템으로 통합하여 AI 기반의 가치 창출 시간 및 결과를 가속화해 획기적인 솔루션을 제공한다"고 말했다.
◆완성된 머신러닝 솔루션으로 AI의 잠재력 극대화 = IDC가 지난 2월에 발표한 자료에 따르면, 현재의 기업들은 아직 AI 인프라 성숙기에 도달하지 못했으며, 이는 특히 AI 제품과 서비스를 개발에 요구되는 실험 또는 프로토타입 단계를 가속화하고자 하는 기업에게 무엇보다 중요하고 많은 투자비용이 요구되는 부분으로 밝혀졌다.
일반적으로 AI 인프라 채택을 통해 규모에 최적화된 모델 개발 및 학습을 지원하려면 구입, 구축 및 고도의 유연한 소프트웨어 환경 관리 등의 복잡한 여러 프로세스 및 전문 컴퓨팅, 스토리지, 상호 연결 및 가속기를 포함하는 인프라가 요구된다.
HPE 머신러닝 개발 시스템은 기업에 소프트웨어, 가속기, 네트워킹, 서비스와 같은 전문 컴퓨팅을 결합한 솔루션 제공으로 AI 인프라 도입과 연관된 복잡성을 해소하고 즉시 규모에 최적화된 머신러닝을 구축 및 학습을 제공한다.
HPE 머신러닝 개발 시스템은 머신러닝 알고리즘의 핵심인 첨단 분산형 훈련, 자동 하이퍼 파라미터 최적화 및 신경 아키텍처 검색으로 더욱 빠르게 모델 정확도를 개선할 수 있도록 돕는다.
HPE 머신러닝 개발 시스템은 GPU 32개의 소규모 구성부터 256개의 대규모 구성까지 다양한 워크로드를 위한 모델을 효율적으로 확장할 수 있다. 2개의 GPU로 구성된 소규모 구성에서는 자연어 처리 및 컴퓨터 비전과 같은 워크로드에 대해 약 90%의 확장 효율성을 제공한다. 내부 테스트 결과에 따르면, HPE 머신 러닝 개발 시스템의 GPU 32개 구성은 타사 동일 수준 제품과 대비해 최대 5.7배 더 빠른 속도의 NLP 워크로드와 함께 최적의 상호 연결성을 제공한다.
◆즉시 사용 가능한 AI 모델 개발 및 학습 솔루션으로 POC 운영 속도 향상 = HPE 머신러닝 개발 시스템은 고객 규모에 최적화된 턴키 모델 개발 및 학습을 위해 사전에 구성되거나 미리 설치된 AI 인프라를 하나의 통합 솔루션으로 제공한다.
HPE 포인트넥스트 서비스는 해당 서비스의 일환으로 현장 설치 및 소프트웨어 세팅 서비스를 제공함으로써 사용자가 머신러닝 모델을 즉각적으로 도입하고 학습할 수 있도록 지원하며, 사용자는 데이터를 통해 보다 빠르고 정확한 인사이트를 얻을 수 있다.
HPE 머신러닝 개발 시스템은 소규모 빌딩 블록을 시작으로 스케일업 옵션도 제공하며, 소규모 빌딩 블록 구성은 다음과 같다.
◾기업이 PoC에서 생산까지에 이르는 고품질 모델을 신속하게 개발, 반복 및 확장할 수 있도록 지원하는 HPE 머신 러닝 개발 환경을 갖춘 혁신적인 머신러닝 플랫폼
◾고성능 컴퓨팅용 엔비디아 A100 80GB GPU 8개 구성으로 시작하는 HPE 아폴로 6500 젠10 플러스 시스템을 활용해 AI 모델을 학습하고 최적화할 수 있는 대규모 특수 컴퓨팅 기능을 제공하는 최적화된 AI 인프라
◾시스템 관리 소프트웨어 솔루션인 HPE 퍼포먼스 클러스터 매니지먼트(Performance Cluster Management)를 통해 세분화된 중앙 집중식 모니터링 및 관리를 바탕으로 최적의 성능을 제공
◾HPE 프로라이언트 DL325 서버 및 1Gb 이더넷 아루바 CX 6300 스위치를 사용해 시스템 구성 요소 제어 및 관리 스택 제공
◾엔비디아 퀀텀 인피니밴드 네트워킹 플랫으로 컴퓨팅 및 스토리지 커뮤니케이션 성능 보장
